
La arquitectura web es la base con la que siempre se debe comenzar el diseño de cada sitio web. Aunque hoy en día los robots de los buscadores están suficientemente desarrollados para poder rastrear básicamente la gran mayoría de páginas web, la estructura adecuada puede tener un impacto positivo o negativo en el proceso de posicionamiento web.
Los sitios diseñados sin una planificación correcta no sólo disminuyen su oportunidad de lograr posiciones más altas, sino también arriesgan que sus subpáginas más importantes sean completamente ignoradas por Google.
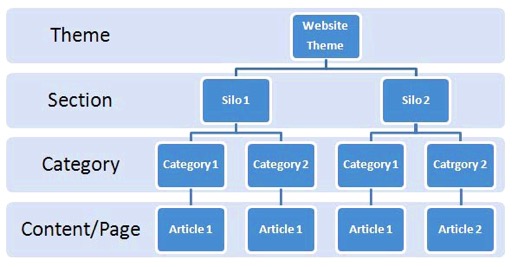
¿Qué es la arquitectura web? Para ser claros, la arquitectura de un sitio web es una idea totalmente distinta del diseño web. En lugar de pensar en cómo se ve físicamente un sitio, más bien piensa en cómo sus subpáginas individuales están conectadas entre ellas. Estas subpáginas deben estar organizadas de tal manera que el usuario final y los robots de buscadores puedan navegar fácilmente entre ellas dentro de un solo sitio. Una estructura ejemplar de una página web simple se podría ver así:
Aunque la arquitectura web correcta es un buen punto de partida, como dice el refrán, el diablo está en los detalles. Descuidar algunos elementos importantes al inicio del proceso puede afectar el SEO a largo plazo. Para prevenirlo, estos son los errores más comunes relacionados en la arquitectura web:
- Enlaces internos
Los enlaces internos permiten que los robots no solo naveguen de manera eficiente por el sitio, sino sobre todo para evaluar qué subpágina debe priorizarse y para qué keywords debe rankear. Por lo general, todas las subpáginas más importantes (por ejemplo, categorías o secciones) deben estar enlazadas desde la página principal y tener más enlaces que las páginas con una prioridad más baja. Por ejemplo, uno de los errores más comunes en las tiendas online es cuando los productos tienen la misma cantidad de enlaces internos que la categoría a la que pertenecen.
Otro elemento importante es ser congruente en cuanto al uso de los textos de anclaje dentro de la página: recuerden, cada anchor text debería llevar a una sola subpágina específica.
- Targetear las mismas keywords en diferentes subpáginas
Si varias subpáginas llegan a competir por las mismas palabras clave, esto puede causar un fenómeno llamado canibalización (sobre la que ya he escrito aquí https://www.merca20.com/canibalizacion-de-palabras-clave-que-hacer-cuando-tu-pagina-compite-con-ella-misma/). Desafortunadamente, el efecto suele ser contraproducente: en lugar de ayudar al posicionamiento, la canibalización disminuye la posición promedio de una página web. Asegúrense de que cada keyword individual tenga su subpágina dedicada.
- Mapas del sitio
Con demasiada frecuencia, los mapas de sitio suelen ser simplemente una lista de todas las subpáginas de un sitio web, mientras que deben contener solo el contenido que realmente queremos rastrear, sin las páginas excluidas por robots.txt, el tag noindex o las que lleven la etiqueta canonical. Eliminen de sus mapas todas las páginas innecesarias antes de enviarlos a Search Console.
- Bloqueo incorrecto de páginas innecesarias
Muy a menudo sucede que las partes de un sitio web innecesarias se bloquean utilizando robots.txt y la etiqueta noindex al mismo tiempo. Esta es una solución errónea; recuerden no mezclar estas dos maneras de limitar el rastreo de ciertas subpáginas y usen una u otra, dependiendo de la situación particular.
- Canonical tag
La etiqueta canonical ayuda a los buscadores a comprender cuál de las páginas similares dentro de un sitio web es la que queremos posicionar. Sin embargo, deben recordar que para los robots de los motores de búsqueda el tag canonical es solo una sugerencia que al final puede ser ignorada. Monitoreen las subpáginas canónicas para poder comprobar que funcionen como lo planeaste.
Es cierto que cuidar estos 5 elementos, por supuesto, no resolverá todos sus problemas, pero seguro les ayudará a evitar los más comunes. ¡Buena suerte!







